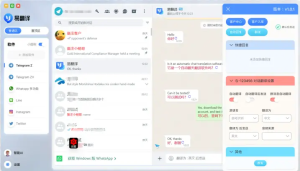
易翻译的拍照功能集中在“拍照取词翻译”模块,既可直接用相机拍照也可导入相册图片,借助OCR把图片文字识别并翻译。功能常含整图翻译、框选取词、批量识别与多语种支持,适合菜单、路牌、教材、标签及清晰手写体等场景,识别效果受分辨率、光线与字迹影响。建议在光线好且字体清晰时拍摄,以提高识别率。并可裁切。测试

先把“能拍照”拆成三件事来想
费曼法告诉我们:如果你能把复杂的东西拆成简单的块,并像对朋友解释那样讲清楚,别人就能理解。关于“易翻译哪些能拍照”,我们可以按三步来拆:
- 识别(拍照并提取文字):这一步是把图片里的文字变成可处理的文本,称为OCR。
- 翻译(把提取的文字翻成目标语言):把OCR得到的内容交给翻译引擎处理。
- 呈现与编辑:翻译结果展示、可选择框选、修正或将翻译结果复制/保存。
易翻译里哪些界面可以拍照?(通俗说法)
简短地说,所有需要把“图中文字”变成“翻译文本”的地方,都可以用拍照来解决。具体表现为几个常见入口:
- 拍照取词翻译模块:这是核心入口,专门用于拍照或导入图片进行OCR并翻译。
- 相册/截图导入:如果你已经有照片或截图,可以从相册导入进行识别。
- 实时相机预览(若有):部分版本会提供实时预览取词或整句实时翻译,像“相机对着菜单直接看到译文”。(不同版本表现可能略有差异)
这些入口适合拍哪些“东西”
- 印刷体文本:招牌、说明书、书本、菜单、标签、票据等 —— 识别率高。
- 清晰手写体:笔迹规范、对比度高的手写通常可以识别,但效果不如印刷体。
- 屏幕文字与截图:电子屏幕截图、网页或PPT截屏通常识别非常好。
- 混合场景:包含图像与文字的海报、包装、路牌,依文字清晰度决定效果。
为什么有时拍了也识别不准?把原理讲清楚
要像费曼那样解释,就要把难点讲明白。OCR并不是读“意思”,它是识别“像素里构成字符的形状”。想象把文字当成由黑白小方块拼成的图案:
- 如果方块清楚(高分辨率、对比强),识别就容易。
- 若方块模糊(低分辨率、手抖、反光),OCR就容易把“n”看成“ri”。
- 另外,语言模型会根据上下文猜测最合理的词,但猜错就是常见问题,尤其是专有名词与行业术语。
功能表:各种拍照场景与建议
| 场景 | 适合程度 | 建议 |
| 菜单/路牌 | 高 | 避开强反光,拍直视角度,靠近并裁切文字区域 |
| 教材/书籍 | 高 | 放平,保持光线均匀,使用分段拍照避免歪曲 |
| 票据/收据 | 中等 | 注意小字体和折痕,可以放在平整背景上并加大对比 |
| 手写便条 | 低到中 | 字迹工整时效果较好,潦草手写常识别困难 |
| 图片内文字(海报、包装) | 中 | 复杂背景会干扰,尝试框选文字区域再识别 |
操作流程(像教朋友那样一步步说)
下面是一套通用流程,实操时会很顺:
- 打开易翻译,进入“拍照取词翻译”模块。
- 选择“拍照”或“导入相册”。如果对着场景拍,尽量稳住手机并靠近目标区域。
- 拍完后用框选工具圈出你要翻译的文字段落,必要时放大预览确认识别的文字是否正确。
- 选择源语言与目标语言(若不确定源语言,可开启自动检测)。
- 查看翻译结果,必要时手动修正识别错误或复制结果用于其他应用。
遇到常见问题怎么办?(实用小技巧)
- 识别出来是乱码或词语错误:先检查拍照是否模糊,尝试重新拍,或裁切只保留文本区域;必要时手动修正识别文本后再翻译。
- 文字被遮挡或折叠:尽量把文件摊平或调整角度,避免强烈阴影。
- 多语言混合:启用自动检测或分段识别,再分别翻译。
- 隐私担忧:留意应用的隐私设置与是否上传云端处理,敏感文件可以先行脱敏或在离线模式下处理(如果提供)。
真实场景示例(生活气息)
上午我在街边想点早餐,看到一个全英文菜单,用易翻译拍照取词,快速把每道菜名和配料识别出来;出国旅游时,把路牌、注意事项拍一下,翻译成中文,省了不少猜测时间。学生做笔记时拍教材上的图表,再框选文字,粘到笔记里,查阅更方便。总之,拍照功能像随身放大的“读文字器”。
几点补充的提醒(别忘了)
- 光线比滤镜更重要:哪怕是最好的算法,也斗不过明亮均匀的光线。
- 适当裁切:先裁切再识别,通常比整图识别准确。
- 特殊格式(表格、竖排、复杂公式)效果有限:对表格或数学公式,OCR可能拆分错位,手动校对必要。
为何把这些说得那么细?
其实是因为拍照翻译看似“点一下就好”,但体验好坏完全取决于拍摄时的小动作。像费曼那样,我把原理和步骤讲清楚,是希望你在需要时能快速判断该怎么拍、拍什么以及如何处理异常情况,这样工具才能真正帮到你,而不是只靠运气。
要是你现在拿着某张图片,不妨按上面的流程试一次:先裁切文字区域,确保光线,选对语言,看看识别结果,必要时再微调——这样大多数情况下就能得到满意的翻译了。